Flagship Systems Platform
Atlas AI
Updated: May 2026
View Repository →Built a distributed AI infrastructure platform focused on transformer systems, distributed training behavior, inference optimization, observability, and performance engineering under real systems constraints.
- • Transformer infrastructure + KV-cache systems
- • Distributed runtime & communication profiling
- • Serving, observability, and benchmark automation
Problem
Modern AI systems are constrained not only by model quality, but also by communication overhead, memory scaling, inference latency, synchronization cost, and observability limitations. Atlas AI explores these problems through a systems-oriented infrastructure platform.
System Design
- • Reverse-mode autograd + optimizer infrastructure
- • Transformer runtime with KV-cache and streaming generation
- • Distributed multiprocessing runtime with communication profiling
- • FastAPI inference server with observability endpoints
- • Benchmark automation and regression detection workflows
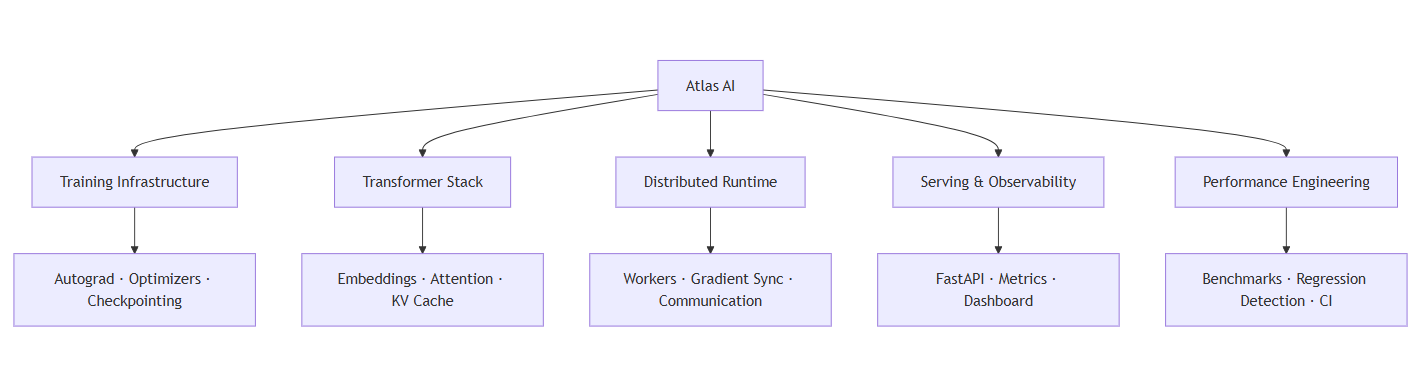
Architecture
Atlas AI integrates training infrastructure, transformer systems, distributed runtimes, serving infrastructure, and observability into a unified ML systems platform.
Results & Insights
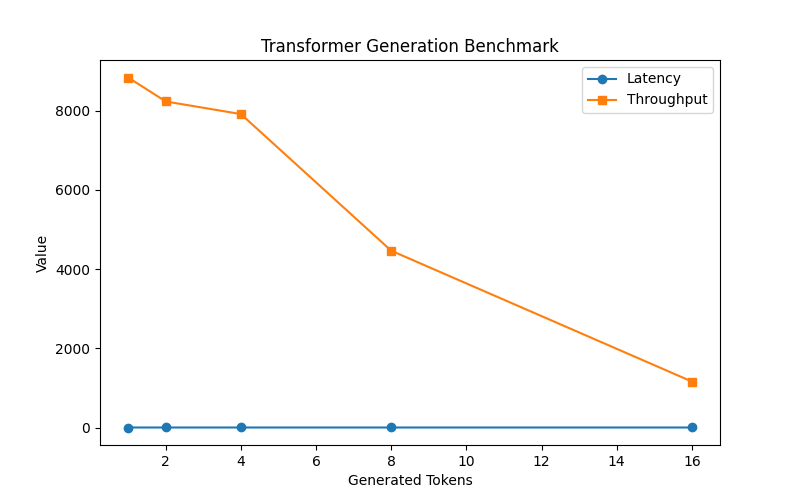
- • Observed throughput degradation as autoregressive sequence length increased
- • Communication profiling exposed scaling bottlenecks in distributed runtimes
- • KV-cache growth significantly impacted transformer memory behavior
- • Streaming generation reduced perceived inference latency
- • Benchmark automation enabled regression-oriented infrastructure validation
Transformer Benchmark
Transformer generation throughput decreases as token count increases, revealing inference scaling and KV-cache effects.
Serving & Observability

Takeaway: Modern AI systems are fundamentally constrained by memory behavior, communication overhead, inference latency, and observability — not just model architecture.
Technical Stack
Python · Transformers · FastAPI · Distributed Systems · Observability