Project Case Study
Distributed Training Simulator
Updated: May 2026
View Repository →Built a distributed training simulator to analyze scaling behavior, communication overhead, and system-level bottlenecks in data-parallel machine learning workloads.
- • ~0.77 efficiency (small models)
- • Compute → communication bound at ~8 workers
- • Negative scaling for large models (1000MB)
Problem
Distributed training is often assumed to scale linearly, but in practice communication overhead, model size, and network bandwidth limit performance. This project simulates distributed systems behavior to understand when and why scaling breaks down.
System Design
- • Data-parallel training with worker-level computation
- • All-reduce communication (Ring and Tree strategies)
- • Step time, speedup, and efficiency modeling
- • Communication ratio and bottleneck detection
Architecture
The simulator models distributed training with compute and communication phases, followed by synchronization barriers across workers.

Results & Insights
- • Near-linear scaling achieved for small models (~0.77 efficiency)
- • Transition from compute-bound → communication-bound at ~8 workers
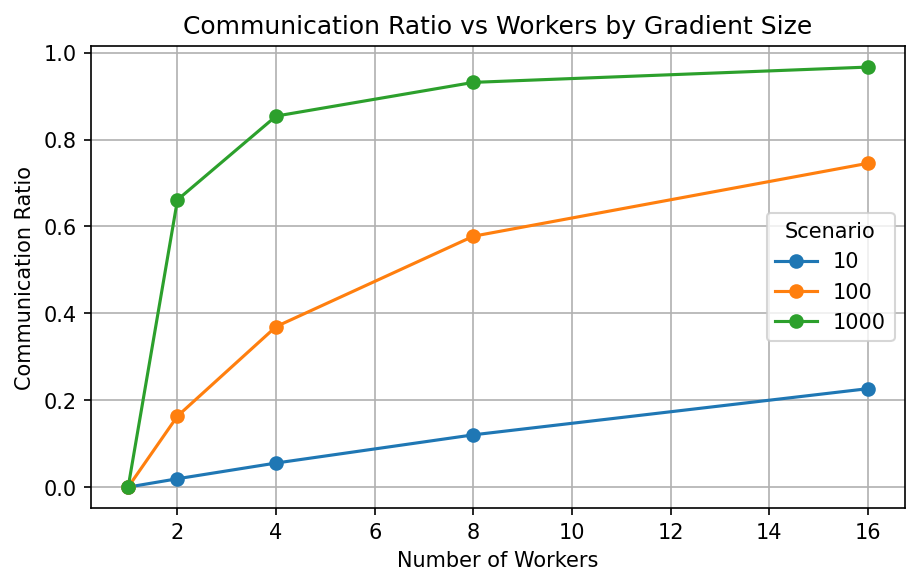
- • Large models (1000MB) showed negative scaling due to communication cost
- • Network bandwidth strongly impacts scalability (1GB/s vs 100GB/s)
- • Ring all-reduce outperformed tree strategy at higher worker counts
Communication Ratio
Scaling Behavior
Step time, speedup, and efficiency vary significantly with worker count, revealing system bottlenecks at scale.
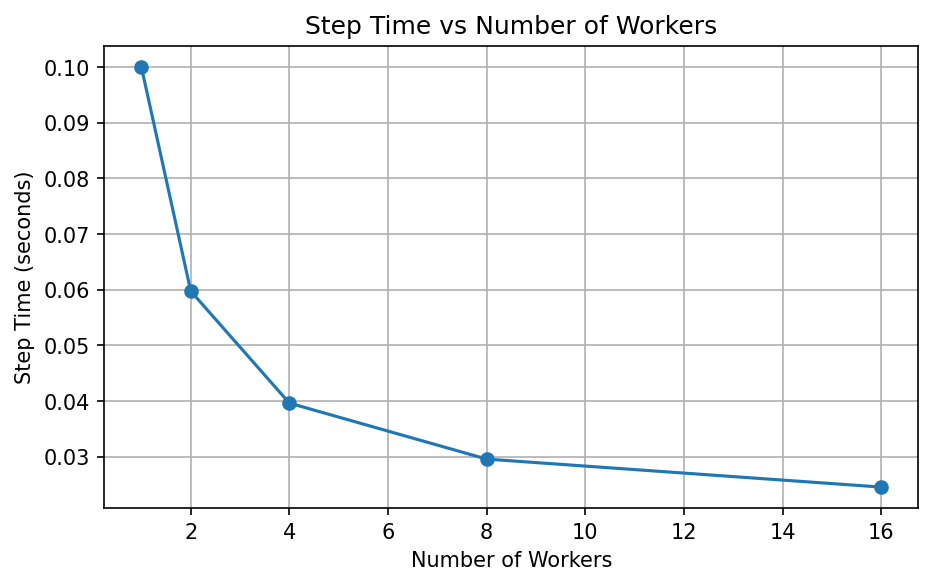
Takeaway: Distributed training stops scaling efficiently when communication overhead begins to dominate computation.
Technical Stack
Python · Distributed Systems · All-Reduce · Performance Modeling