Project Case Study
Distributed Training Profiler
Updated: May 2026
View Repository →Built a systems-oriented profiler for analyzing communication overhead, memory bottlenecks, scaling efficiency, and distributed training behavior in large-scale ML workloads.
- • Communication vs compute bottleneck analysis
- • ZeRO memory optimization simulation
- • Scaling efficiency & overlap analysis
Problem
Large-scale distributed training is constrained by communication overhead, GPU memory limits, and synchronization bottlenecks. Understanding these trade-offs is critical for efficient LLM and distributed ML training.
System Design
- • Distributed training step simulation
- • Ring all-reduce communication modeling
- • Communication-computation overlap analysis
- • GPU memory feasibility estimation
- • ZeRO-1 / ZeRO-2 / ZeRO-3 optimization modeling
Architecture
The profiler models distributed training behavior across communication, memory, and scaling dimensions to identify bottlenecks and optimization opportunities.
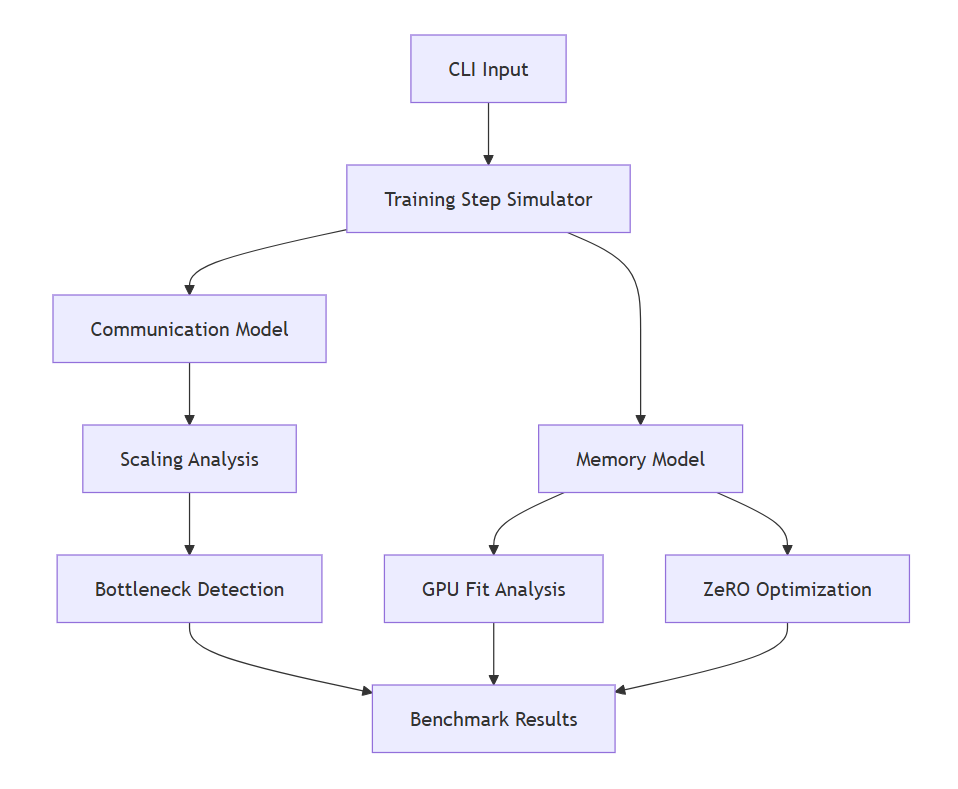
Results & Insights
- • Communication overhead increases significantly with worker count
- • Scaling efficiency degrades as synchronization dominates execution
- • Communication-computation overlap reduces effective synchronization cost
- • Large models rapidly become memory-bound
- • ZeRO optimization dramatically reduces memory requirements
Scaling Analysis
Scaling behavior demonstrates how communication increasingly dominates training step time as worker count grows.
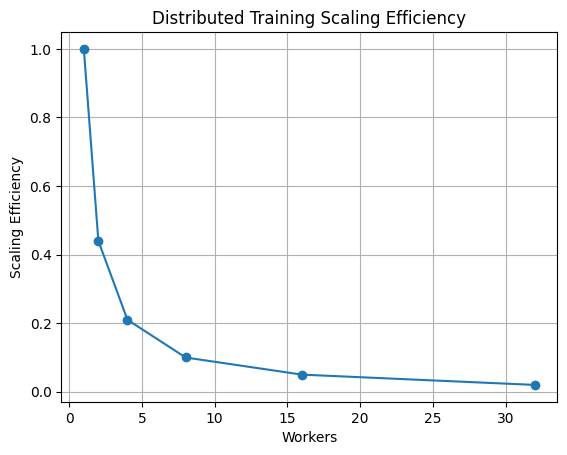
Takeaway: Large-scale ML training is fundamentally constrained by communication and memory systems, not just compute throughput.
Technical Stack
Python · Distributed Systems · Memory Modeling · Performance Analysis